


A gépi tanulás az egyik alapvető sarokköve, sok esetben szinonimája az AI technológiáknak, (az NLP és az RPA mellett, például). Ebben a cikkben a gépi tanulás néhány alapvető módját mutatjuk be, ahogy gépeket és robotokat szokás ma “betanítani”.
Robot Látás - a gépi látás, mint a betanítás elsődleges eszköze
A betanítás egyik alapvető módja a vizuális információ betáplálása, majd annak meghatározása, hogy mit kell ezzel az információval kezdenie a rendszernek.
Gépi látásról akkor beszélhetünk, ha a számítógéphez valamilyen kamerakép is csatlakozik. A gép feladata itt az, hogy a kamerán érkező vizuális adatokhoz rendeljen hozzá valamilyen munkavégzést.
Ez a munkavégzés a robotikában lehet vezető-útmutató (guidance) jellegű, vagy automatikus ellenőrzés (inspection).
A gépi látást robotikában robot látásnak is nevezik. A gép és a robot között a kinematikában van különbség: a robot képes lehet a környezetének fizikai megváltoztatására. Tehát ha egy gép képi adatokat rögzít és maximum szoftveres következményeket csatol a leolvasott adatokhoz, akkor az inkább gépi látás, de ha a gép definiált referenciakeretekkel rendelkezik (ismeri saját és a céltárgyak pozícióját és képes ennek a pozíciónak a módosítására), az már inkább a robotika, a robot látás területéhez tartozik.
“Látás” alatt nem feltétlenül csak spektrálisan, fényalapon kinyert információt értünk, hanem bármilyen képalkotási módszert, vagyis ez lehet radar, a nagyon felfutóban lévő LIDAR, vagy ultrahang is - az autonóm járművek fejlesztésében ezek az észlelőeszközök is fontos szerephez jutnak.
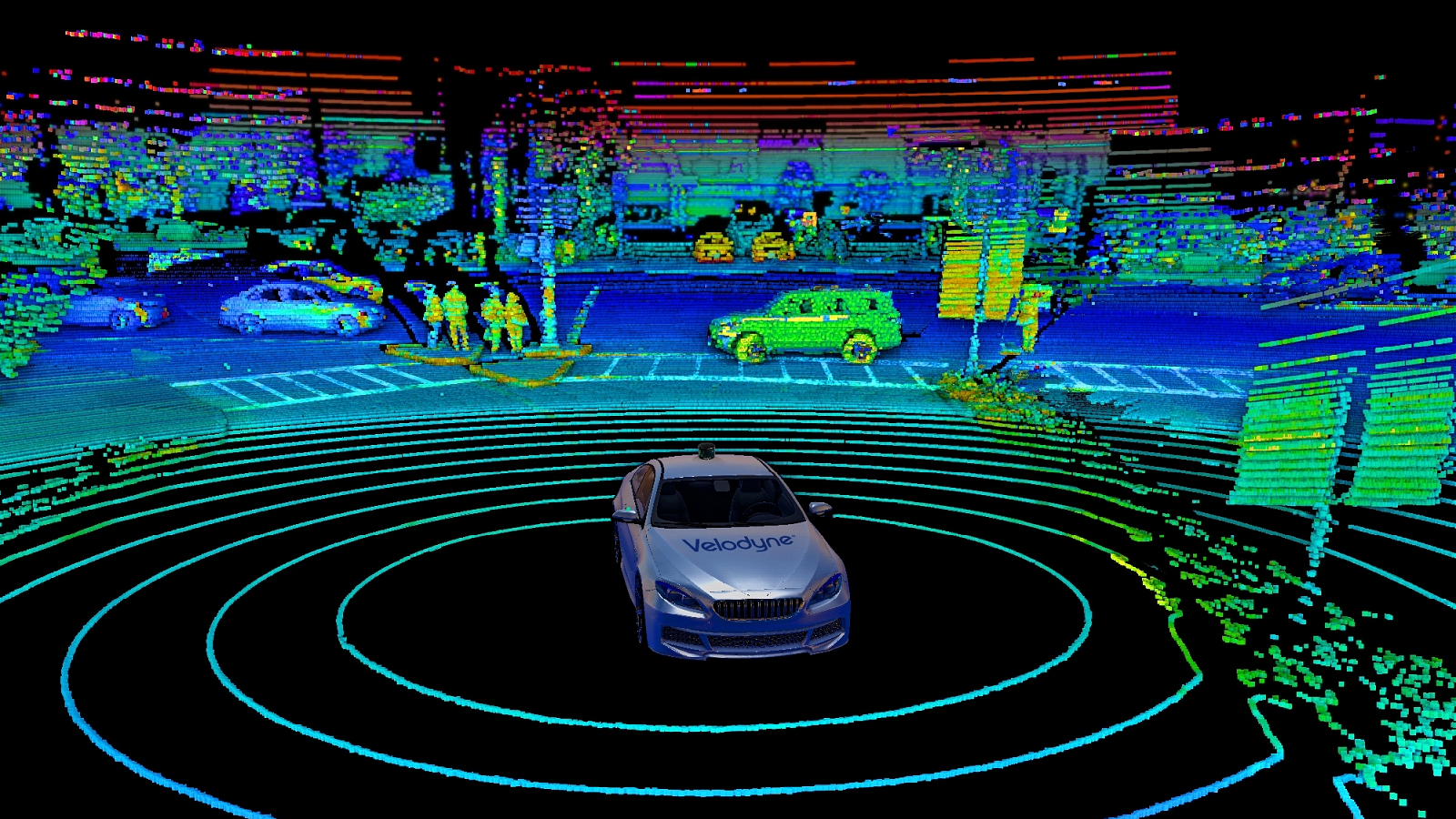
A gépi látásnak nyolc különböző felhasználási módját és hatféle elemzési módszerét mutattuk be ebben a blogposztunkban.
Supervised Learning - tanulás teljes betanítási folyamattal
A supervised learning olyan tanítási folyamat amely egy előkészített (kurált, válogatott) adathalmazzal történik. Ebben az esetben a gépbe betápláljuk az induló adatkészleteket is, és a kívánt eredményekre hozott példákat is. Ezt hívjuk tanítóadatnak: gyakorlatilag konkrét példákat tartalmaz arra a tevékenységre, amit a gépnek végeznie kell.
Például el szeretnénk érni, hogy egy képelemző szoftver meg tudja állapítani, hogy van -e macska egy képen, vagy nincs. Ekkor megmutatjuk a képet, az algoritmus lefut, hoz egy eredményt, majd megnézi a megoldást mondjuk egy a rendelkezésére bocsájtott szövegfájlban, és összeveti a saját eredményével. Ha az eredmény helyes, akkor abba az irányba tolódik a modell belső működése, hogy “ha hasonlót lát”, akkor ezt az eredményt kell hozni.
A tanítás ezután úgy folytatódik, hogy az algoritmust elkezdjük lefuttatni, de a helyes választ már nem mutatjuk meg. Ekkor ellenőrizni kell az eredmények pontosságát, és a rossz válaszokat kigyűjtjük, és újra felhasználjuk tanítóadatként, vagyis helyes válasszal együtt. Ezekkel az iterációkkal válik egyre pontosabbá az algoritmus.
Megfelelő mennyiségű példa megismerése után (ezeket hívjuk iterációs optimálásnak) a gép meg tudja jósolni, hogy az új inputok milyen eredményekhez vezetnek majd, méghozzá matematikai transzformációk segítségével. Gyakorlatilag megkeresi azokat a bonyolult képleteket, amelyek az adott eredményhez vezetnek.
A gép által kidolgozott funkció akkor lesz optimális, ha helyesen meg tudja jósolni egy olyan kiindulópont végeredményét, amely kiindulópont nem volt része a tanítóadat-sornak.
Egyszerű, kézzelfogható példa mondjuk a kézírás, vagy a hangfelvétel elemzése: a bemenő adat (scannelt kéziratok és hangfelvételek) mellé odatesszük a “megfejtést” (digitalizált szöveges leiratok). Ha ezt kellően nagy számban végezzük, akkor a gép képessé válik bármilyen kézirat vagy hangfelvétel “legépelésére”. (Természetesen a valóságban még számos adattudományi és szoftvermérnöki munka van a háttérben, ezért van az, hogy még csak napjainkban kezdenek általánossá válni az ilyen algoritmikus alapon működő szoftverek, mint például a magyar nyelvre megfelelő megoldást biztosító AIrite)
Ilyen címkézési feladatot végeztünk el akkor, amikor egy biztosítótársaság szoftverét tanítottuk be a kárjelentésekhez csatolt fotók szűrésére, vagy amikor a számlaelemző szoftvert tanítottuk meg arra, hogy melyik számsor pontosan milyen típusú adatot jelent egy bármilyen, nyomtatott számla scannelt képén.
Automatizált Supervised Learning
Ez alatt azt értjük, hogy a tanítóalgoritmus megépítése valamilyen automatizációnak köszönhetően emberi beavatkozás nélkül megtörténik. Ezt a legegyszerűbben úgy kell elképzeni, hogy a gép vagy robot számára kétféle adatforrást biztosítunk. Például elhelyezünk rajta egy közelségi szenzort (bármilyen eszközt, ami hasonlít mondjuk egy tolatóradar működéséhez) és egy kamerát. A kamera “messzebbre lát”, mint a szenzor, de a gép magától még nem tudja, hogy milyen kamerakép tartozik egy közeledő tárgyhoz. A szenzor viszont érzékeli ha valami túl közel jön és ezt rögzíti a gépünk, majd összeveti a kameraképpel: hogy néz ki a videón az, amikor van valami előttem? (pontosabban: amikor jelez nekem a közelségi szenzor).
A dolog egyik lehetséges kifutása az, hogy a gép nemcsak megtanulja, hogy néz ki az, amikor valami van előtte, és ezért a szenzor használata nélkül, csak a kamerakép elemzésével is döntést tud hozni, hanem az, hogy mivel a kamera messzebb ellát, ezért azt is meg tudja tanulni, hogy néz ki az a kép, amit amikor lát, amikor valami hamarosan a közelségi szenzor hatókörébe fog érni.
De ne menjünk ennyire messzire: maradva az eredeti funkcionál, ha nem kötnénk be a közelségi szenzor adatait a gépbe, mert mondjuk nem áll ilyen rendelkezésre, akkor milyen lehetőségünk van a gépünk betanítására? Nem marad más módunk, mint a videófelvételek felcímkézése: ezen van objektum, ezen nincs (szabad a pálya). Ezt emberi munkaerővel, egyenként kell megtenni. Ez a “supervised learning”, a felügyelettel végzett tanulás. A “self-supervised” módszer lényege, hogy mentesíti az emberi munkaerőt a betanítás manuális fázisa alól, valamilyen kereszthivatkozásos, automatizált tanítási módszer segítségével.
Még egyszerűbben: a supervised learning kapcsán említett címkézési folyamat automatizálása egy algoritmikus eszköz segítségével.
Unsupervised Learning - tanulási folyamat visszajelzés nélkül
Az unsupervised learning, vagyis felügyelet nélküli tanítás során a számítógép vagy robot munkáját nem segíti korrekció. A gép megfigyeli az adatsor sajátosságait, és ezeket a sajátosságokat képes felismerni a következő adatsorban. Erre lehet példa a gépi látásról szóló cikkünkben szereplő macskás projekt: Ha sok macskás képet mutatunk a gépnek (és csak annyit közlünk vele, hogy a képen van macska), akkor egy teljesen új képről is meg tudja majd állapítani, hogy szerepel -e rajta macska, vagy nem, annak ellenére, hogy még csak közelítő definíciói sincsenek a “macska” elvont fogalmáról - kizárólag képpontok absztrakt egymáshoz képesti elrendeződéseit keresi.

A self-supervised learning során csak bemenő adat van, nincs tanítóadat, nincs korrekció. Általános képet alkot a bemenő adatok jellegéről. Ez arra lesz jó, hogy a későbbiekben (szaknyelven: “downstream”) a feladatot rövidebb betanítás után meg tudja oldani.
Például képfelismerésnél a képek felcímkézése rendkívül erőforrásigényes, ha automatizációra nincsen lehetőségünk. Egyesével kell létrehozni a tanítóadatokat (supervised úton), és ez nem mindig kivitelezhető. Az egyik tipikus út ilyenkor az, hogy a képek közepét kivágjuk vagy szétszabdaljuk, és a darabjait összekeverjük (hiszen ezek könnyen automatizálható folyamatok, egy sor kóddal megoldható a hosszadalmas egyenkénti címkézés helyett), és az algoritmus feladatává tesszük, hogy egészítse ki a képet, vagy helyezze a megfelelő sorrendbe. Ehhez semmit nem tud használni, csak az általa már ismert képek összességét, de ez elegendő információ (“világkép”), ezzel már a probléma kereteit képes feltérképezni, és valamilyen megoldást fog szállítani. Amikor ezt a feladatot már kellően sokszor végrehajtotta, és egyre jobb megfejtéseket produkál, akkor az azt jelenti, hogy a problémakör egészét kezdi már lefedni, és ha ezután elkezdjük supervised módon tanítani egy konkrét feladat ellátására, akkor lehet, hogy 10-20 címkézett képpel el tudunk érni olyan eredményt, mint amihez mondjuk 1000 vagy 5000, emberi munkával címkézett kép kellett volna az unsupervised tanulási folyamat nélkül.
Minőségbiztosítás gépi látással: anomália-észlelés
A gépi látás egyik oldalági alkalmazása lehet az anomália-észlelés, ez egy tipikus Unsupervised Learning-probléma. Egy kameraképpel betanítjuk a gépet arra, hogy néznek ki a megfelelő termékek a gyártósoron. A feladata innentől az, hogy bármilyen eltérés (anomália) esetén jelezzen. Ezt a félvezető szíliciumlapkák gyártásakor használják például, de bármilyen ipari minőségbiztosítási kihívásnál hasznos lehet.
Imitation Learning - tanulás emberi tevékenység utánzásával
A szenzorok használata lehetővé teszi, hogy demonstráció révén is betanítsunk robotokat. A betanítás folyamata nagyon emlékeztet arra, mint amikor egy emberi munkásnak mutatjuk meg, hogy mit kell csinálni.
Ebben az esetben a kép tényleg többet mond ezer szónál, érdemes megnézni ezt a kétperces videót a demonstrációról:
Az, ahogy a kezünket használjuk dolgok megragadására, számunkra rendkívül egyszerű és magától értetődő, de leprogramozni kész rémálom lenne. A fenti kísérletben inkább lekövették, milyen mozgást végeznek az emberi kéz részei és a megadott kontaktpontokat “warpolták” a robotkéz ujjaira, majd optimalizálták a végrehajtásokat.
Reinforcement Learning - tanulás tapasztalati úton
A reinforcement learning legegyszerűbben a tevékenység alapján tanulást jelenti. A gépnek csak egy fix visszajelzési módra van szüksége. Ennek legegyszerűbb példája a videójáték: a cél az, hogy minél magasabb pontszámot érj el!

A gép ezután véletlenszerűen adja a parancsokat (gáz, fék, jobbra, balra), és ahogy teljesíti a kanyarokat és sikeresen kerüli az akadályokat, úgy fog emelkedni a pontszám, amit elér.
Ehhez csak arra van szüksége, hogy minden egyes tevékenységhez kapjon egy visszajelzést: segítette ez a tevékenység a célt, hátráltatta, vagy semleges volt?
Egy idő után meg fogja nyerni az autóversenyt, annak ellenére is, hogy a pályarajzról egyébként fogalma sincs.
A robotikában nem képleteket keres a gép, hanem cselekvéseket. Azt figyeli, hogyan tud egyre nagyobb “pontszámot” elérni. Ehhez hasonló módszerrel tudnak például egyre gyorsabban és stabilabban futni a négylábú robotok.
Multi-Agent Learning - egymástól tanulás
Az egyszerre több szereplő (ágens) közreműködésével létrejövő, hálózatba kapcsolt önálló robotok egymás tapasztalataira is tudnak építeni, akár valósidőben is. Ez a Reinforcement Learning egy speciális alesete, amikor a megerősítést egy másik ágens nyújtja.
Ennek a tanulási módnak az egyik leglátványosabb reprezentációja a “drónflotta”, amikor egymás adataihoz hozzáférő önvezető drónok mozgás közben egymáshoz alkalmazkodva alakzatokba rendeződnek.
Ösztönösen azt gondolhatnánk, hogy ez könnyebbé teszi a tanulási folyamatot. Valójában azonban megnehezíti, mert a robot cselekszik, megvizsgálja az eredményt, és ugyanarra a cselekedetre más eredményt is kaphat, hiszen közben egy másik robot is beavatkozott a rendszerbe. Ez az ellentmondás még ma sincs feloldva teljes mértékben, a vonatkozó kutatások évtizedek óta zajlanak. Az ilyen rendszerekben a pontos “cél” meghatározása meglepően komoly kihívás.
De ez nem jelenti azt, hogy ne találnánk Multi-Agent Reinforcement Learning alkalmazásokat már most is, például a telekommunikációban, a gazdaságban, bárhol, ahol az irányítás elosztására van szükség, mert az előforduló esetek száma túl magas ahhoz, hogy előre beprogramozzuk az összes viselkedésmódot.
Ezek voltak tehát az ipari és robotikai tanulórendszerek főbb, jelenleg használatos típusai.
Egy hosszú út elején járunk még, de már most is látványos megoldásokat tudunk nyújtani számtalan olyan gépészeti problémára, amire akár 10 évvel ezelőtt sem voltak még képesek a számítógépes rendszerek. Ha szeretné megismerni a konkrét példákat az ilyen megoldásokra, akkor nézze meg ezt a 10 megállapítást a gyártóipar és a machine learning összefüggéseiről!
Ezen a blogon továbbra is folyamatosan be fogunk számolni a Gépi Tanulás újdonságairól, az újabb határvidékek meghódításáról.
Ha a szeretné felkészíteni szervezetét az AI-technológiák által alakított, új piaci környezetre, kérjen konzultációt!
Szeretne többet tudni a témakörről? Adja meg elérhetőségét és értesítjük az új blogbejegyzésről.